近期打算写一个面向LOSF的简单的磁盘空间分配器,就在这里记录一下设计思路吧。
如果不了解LOSF问题的话,可以先看看这两篇文章
Background research
磁盘空间分配器设计的核心就是设计一套可以记录磁盘空间的数据结构,然后完成相应接口的实现。
比如我们可以先将磁盘上的连续空间分割成 4KB 大小的 blocks,然后用一个 bitmap 来记录每个 block 的使用情况,然后实现Allocate和Free接口后就是一个简单的分配器了(使用链表/查找树来记录空闲的区间亦可)。
所谓治学先治史,如果想要设计一个适用的分配器,就有必要先参考一些现有的文件系统设计的原理及其优缺点,比如 ext系, FAT系, NTFS,以及一些面临LOSF考验的文件系统,比如 WekaFS, CephFS, HDFS 等。此外,内存分配器本质上也是类似的(地址空间分配),可以参考他们的池化设计思路。
块设备特性
不同的块设备会有不同的物理特性影响到它的性能,无论是HDD还是SSD,连续读写的性能都好于随机读写。
对于 HDD 的原理大部分人都了解,这里不做过多赘述。由于在数据读写前需要先由电机驱动摇臂,让磁头对准磁道,因此随机读写性能极差,会增加大量的磁头寻道时间。
另外 HDD 有两种寻址方式:CHS:将硬盘划分为磁头 Heads、柱面 Cylinder、扇区 Sector,这种寻址方式已经过时;LBA:逻辑块寻址模式,一次io请求可以读取连续多个扇区(连续读写还能减少io次数)。
目前(2020s)的SSD都是基于NAND闪存的,NAND闪存芯片的数据存储单元是一个类似于MOS管的电压控制型三端器件,其数据的擦除和写入也跟MOS管工作原理一样是基于隧道效应(半导体中发生的量子隧穿效应)的,电流穿过浮置栅极与硅基层之间的绝缘层,对浮置栅极进行充电(写数据)或放电(擦除数据)。其中向浮栅中注入电荷表示写入了’0’,没有注入电荷表示’1’。
NAND闪存的读取原理是:通过浮置栅极的电压来判断是否有电荷存储在栅极中,如果有电压,那么三端器件的源极和漏极就处于导通状态,否则就是截止状态。
PS:还有一种NOR闪存,写入数据的原理是热电子注入。
NAND闪存的特性:
不适用于长期数据存储,因为电荷存储失效的概率更大
不需要寻址,可以直接读写某一页/块(一次io指定地址和长度)
不能覆盖写,只能先擦除,再写入(就像一块黑板,写之前必须先擦干净)
- 磁盘里封装了一个block的结构,擦除操作是以 block 为单位的(较大),写入是以 page 为单位的(较小)
- 基本构成:page(4K)→ block(通常64个page组成一个block)→ plane/die(多个block组成)→闪存片(多个die组成)→SSD(多颗闪存片组成)
- 注意:由于这个特性,ssd在进行修改时,需要先重新分配一块空闲的page,然后将原来的page标记为无效,再将数据写入新的page,这个过程会产生写放大
- 分配器(或SSD的固件)需要能够记录被标记为无效的block,并且找机会将其擦除(这里block内可能有其他的未失效的文件)
- 随机读写会增加io请求的次数:如果是连续读写,一个io请求就能搞定
- 一次io请求会有10us量级的时间开销(包含整个io调用链路)
- 内部的主控芯片负责缓存调度和垃圾回收,因此主控固件的算法对设备性能的影响也很大
- 由于以上特性,固态硬盘的空闲空间越多(连续分配的概率就越大),写放大就越小,读写性能就越高
从上面的特性中我们可以归纳出一些使用SSD的注意事项:
- 避免就近更新 in-place updating:原本用于减少 HDD 寻道时间的优化对 SSD 有副作用。因为包含数据的 SSD 页不能直接覆盖,必须经过擦除步骤
- 冷热数据分离:减少写放大
- 最小数据读写单元是4KB(或8KB 16KB 等),因此尽量保证4KB对齐
- 如果长时间不间断写入,则SSD控制器的后台GC无法异步工作,影响到性能
- SSD 内部支持并行读写,因此可以使用多线程进行小IO读写来提高性能(使吞吐量翻N倍)
除了 HDD 和 SSD 之外,还有光盘,磁带等块设备,精力有限,这就不做过多了解了。
ext2, ext3, ext4
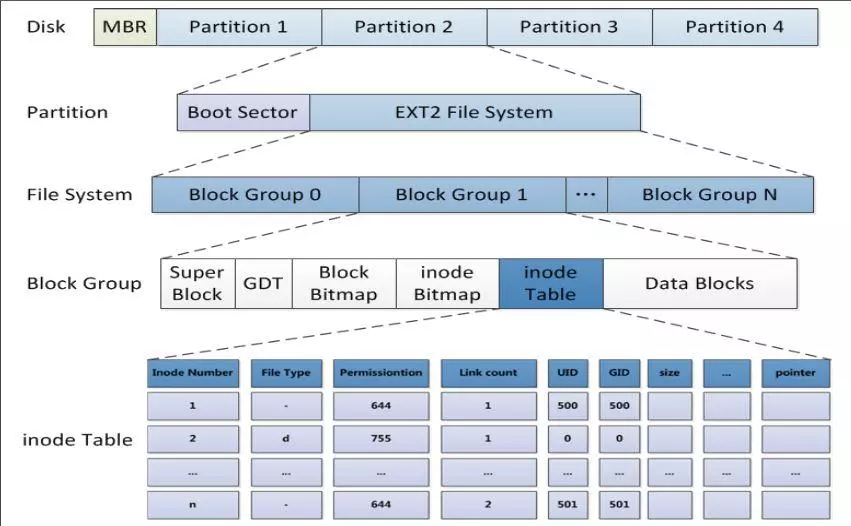
block
block 是 ext 文件系统的基本读写单元,一般大小是4KB。基于block来管理磁盘空间的优点是能减少外碎片,并保证至少4个sector的连续分配,提升部分读写性能,缺点是当需要存储大量小文件的时候会产生内碎片。
inode
由于一个文件的内容在磁盘上可能不是连续的,而是保存在多个block中,因此我们需要一个结构将这些block串联起来,这个结构就是inode(index node)。inode中包含了文件的元数据,比如文件名、文件大小、文件类型、权限、文件储存数据的block数组、一级索引、二级索引等。
文件系统会预留若干block用于保存 inode 表(如果划分了块组,那么每个块组各自维护inode表)。
block bitmap
block bitmap 主要用于磁盘空间管理,是针对文件写入的优化。假如没有block bitmap,我们需要遍历整个磁盘空间来找到空闲block,或者可以通过inode中的block列表来找到文件占用的block,进而算出空闲的block;而bitmap直接为我们提供了一个block占用情况的快照,因此可以大大提高效率。
但当磁盘空间较大时,这种方式的效率也会很低。其原因在于已经写满的连续区间其实不需要每次都扫描,因而我们可以再进行一层针对性的优化:
- 将磁盘空间划分为多个块组,每个块组内都有一个block bitmap,记录该区间内block的使用情况,并记录其使用率。这样,当我们需要分配block时,先遍历块组,跳过使用率过高的部分就能够大大提高效率。(ext2的做法)
- 将小碎片入池,用于未来小文件直接分配
- 尽量连续分配,并使用线段树来管理磁盘空间(ext4的优化)
inode bitmap
用于标识inode占用情况。
如果文件系统比较大,imap本身就会很大,每次存储文件都要进行扫描,会导致效率不够高。同样,优化的方式是将文件系统占用的block划分成块组(block group),每个块组有自己的imap。
block group
block group 前面两段已经介绍了其作用:可以降低分配过程的时间复杂度,均衡利用磁盘空间。
在ext2文件系统中,block 分配策略是每次分配一个,inode 上以数组的形式记录block id(间接块映射),因此在读写大文件时效率极其低下(这一点在ext4文件系统中得到了优化)。
ext3
相比ext2文件系统,ext3多了一个日志功能。
在ext2文件系统中,只有两个区:数据区和元数据区。如果正在向data block中填充数据时突然断电,那么下一次启动时就需要检查文件系统中数据和状态的一致性,这段检查和修复可能会消耗大量时间,甚至检查后无法修复。之所以会这样是因为文件系统在突然断电后,它不知道上次正在存储的文件的block从哪里开始、哪里结束,所以它可能会扫描整个文件系统进行检查。
而ext3文件系统中会新增一个日志区。每次存储数据时,先在日志区中进行ext2中元数据区的活动,直到文件存储完成后标记上commit才将日志区中的数据转存到元数据区。当存储文件时突然断电,下一次检查修复文件系统时,只需要检查日志区的记录,将bmap对应的data block标记为未使用,并把inode号标记未使用,这样就不需要扫描整个文件系统而耗费大量时间。
虽说ext3相比ext2多了一个日志区转写元数据区的动作而导致ext3相比ext2性能要差一点,特别是写众多小文件时。但是由于ext3其他方面的优化使得ext3和ext2性能几乎没有差距。
ext4
回顾前面关于ext2和ext3文件系统的存储格式,它使用block为存储单元,每个block使用bmap中的位来标记是否空闲,尽管使用划分块组的方法优化提高了效率,但是一个块组内部仍然使用bmap来标记该块组内的block。如果要写入一个巨大的文件,扫描整个bmap都将是一件浩大的工程。另外在inode寻址方面,ext2/3使用直接和间接的寻址方式,对于三级间接指针,可能要遍历的指针数量也非常巨大。
ext4文件系统的最大特点是在ext3的基础上新增了mballoc接口,能够一次分配连续的多个blocks,并在inode中使用区(extent,或称为段)的概念来直接映射到一段连续的地址空间。inode寻址方面也一样使用区段树的方式进行了改进。
ext4的结构特征:
ext4在总体结构上与ext3相似,大的分配方向都是基于相同大小的块组,每个块组内分配固定数量的inode、可能的superblock(或备份)及GDT。
ext4的inode 结构做了重大改变,为增加新的信息,大小由ext3的128字节增加到默认的256字节,同时inode寻址索引不再使用ext3的”12个直接寻址块+1个一级间接寻址块+1个二级间接寻址块+1个三级间接寻址块”的索引模式,而改为4个Extent片断流,每个片断流设定片断的起始block号及连续的block数量(有可能直接指向数据区,也有可能指向索引块区)。
ext4删除数据的结构更改。
- ext4删除数据后,会依次释放文件系统bitmap空间位、更新目录结构、释放inode空间位。
ext4使用多block分配方式(multiblock allocator):
在存储数据时,ext2/3中的block分配器一次只能分配4KB大小的Block数量,而且每存储一个block前就标记一次bmap。假如存储1G的文件,blocksize是4KB,那么每存储完一个Block就将调用一次block分配器,即调用的次数为10241024/4KB=262144次,标记bmap的次数也为10241024/4=262144次。
而在ext4中优先分配一个连续的extend,可以实现调用一次block分配器就分配一堆连续的block,并在存储这一堆block前一次性标记对应的bmap。这对于大文件来说极大的提升了存储效率。
为了充分发挥多block分配的优势,ext4 还有延迟分配的特性
pros & cons
最大的缺点是它在创建文件系统的时候就划分好一切需要划分的东西,以后用到的时候可以直接进行分配,也就是说它不支持动态划分和动态分配。由于主要是基于bitmap进行空闲空间管理的,因此对于较小的分区来说速度还不错,但是对于一个超大的磁盘,速度是极慢极慢的。
FAT – File Allocation Table
基本构成:
- 簇:基本的分配单元,大小一般是2KB-32KB,同block
- 文件:由簇链表示,它们不一定在磁盘上是连续存储的,反而通常是离散的。
- FAT:是映射到分区每个簇的条目列表,与bitmap很类似,
- 每个条目记录下列五种内容中的一种:
- 链中下一个簇的地址
- 一个特殊的文件结束符(EOF)符号指示链的结束
- 一个特殊的符号标示坏簇
- 一个特殊的符号标示保留簇
- 0来表示空闲簇
- FAT16每个条目为16位,FAT32每个条目为32位,位数越多,可分配的寻址空间越大(簇也可以分得越细致)
- 每个条目记录下列五种内容中的一种:
- 目录表:是一个表示目录的特殊类型文件(即文件夹,保存在数据区域)。它里面保存的每个文件或目录使用表中的32字节条目表示。每个条目记录名字、扩展名、属性(档案、目录、隐藏、只读、系统和卷)、创建的日期和时间、文件/目录数据第一个簇的地址,最后是文件/目录的大小。
可见,FAT文件系统的核心是FAT表,FAT表不仅承担了类似ext文件系统中bitmap的空闲空间管理功能,还通过目录表这个特殊类型的文件+簇链实现了ext文件系统中inode的文件到地址空间的映射以及目录索引的功能。
exFAT – Extensible File Allocation Table
可以看做是FAT的64位版本,功能性上不如NTFS,但是解决了文件和分区的大小问题。
- Features
- Free Space Bitmap
- Transactional-Safe FAT (TFAT and TexFAT)
- Access Control List (Mobile Windows only)
- Customizable file system parameters
- Valid Data Length
- Pros
- Free Space Bitmap support results in efficient free space allocation
- TexFAT feature in WinCE reduces the risk of data loss
- VDL allows secure pre-allocation.
- Cross-platform support for macOS, Linux, and Windows.
- 分区大小和单文件大小最大可达16EB(16×1024×1024TB);
- 簇大小非常灵活,最小0.5KB,最高达32MB;
- 同一目录下最大文件数可达65536个;
- ExFAT是闪存专用的文件系统;
- cons:
- No support for journaling.
- Vulnerable to corrupt files.
- Limited support by electronic devices.
NTFS
Pros:
- 具有文件压缩、文件权限和文件加密等现代功能
- 是一个日志文件系统,能保证数据的完整性
- 对分区大小没有限制
Cons:
- NTFS 最大的问题是与其他系统的兼容性
- 与其他现代文件系统相比,它相对较慢
- 空间开销很大
HFS+
核心数据结构是一个B-树,B-树中每个节点包含不同记录,记录即Key+Data。节点分为以下四种:
- 头节点(Header Nodes):B-树的第一个节点,其中包含有头记录和位图记录。每个B树只能包含一个头节点。
- 位图节点(Map Nodes):位图节点中只包含一个位图记录。当头节点中的位图记录不足以管理该B-树中的节点分配情况时,就需要位图节点进一步管理。
- 索引节点(Index Nodes):索引节点用来存放定义B-树结构的指针记录。
- 叶节点(Leaf Nodes):叶节点包含与某个关键字相关联的数据记录,每个数据记录的关键字都是唯一的。
APFS
目录结构是B树。
pros:
- Copy on write
- Performance when creating “sparse files” is improved. 意思是说,当创建了一个大文件时并不会让应用程序等待操作系统先写满0,而是先将其标为“allocated”
ZFS
HDFS
是基于 GFS 论文的另一种实现。
WekaFS
CephFS
pooling:ptmalloc, jemalloc, tcmalloc
池化技术的本质是空间换时间,此外还能够做到将多次小请求打包成一次大请求。池化技术的典型代表是内存池,即每次分配内存时,从内存池中分配一个空闲的内存块,每次释放内存时,将内存块归还给内存池。这样,内存的分配和释放就不需要每次都发起耗时的系统调用。此外还有一些其他的池化技术,比如线程池、连接池等。
内存分配的系统调用接口包括 mmap/munmap 和 brk/sbrk,前者用于大内存,后者用于小内存:
mmap的第一种用法是映射磁盘文件到内存中;第二种用法是匿名映射,不映射磁盘文件,而向映射区申请一块内存
1 2 3
#include <sys/mman.h> void *mmap(void *addr, size\_t length, int prot, int flags, int fd, off\_t offset); int munmap(void *addr, size_t length);
brk 的参数为新的brk上界地址,成功返回1,失败返回0;sbrk 的参数为申请内存的大小,返回heap新的上界brk的地址
1 2 3
#include <unistd.h> int brk( const void *addr ) void* sbrk ( intptr_t incr );
allocator: 实现了 malloc() , free()等函数,处在用户和内核之间,提供动态内存管理的支持
- 会预先分配一块大于用户请求的内存, 并通过某种算法管理这块内存
- malloc 优先从空闲空间中分配
- free 掉的内存并不会立即返回给操作系统,而是先放回空闲空间中,减少系统调用次数,避免产生过多内存碎片(池化技术)
glibc ptmalloc2
ptmalloc 内存池的实现如下
利用 chunk 内存块结构组织管理内存
1 2 3 4 5 6 7 8 9 10 11
struct malloc_chunk { INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). 相邻free chunk的合并 */ INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */ struct malloc_chunk* fd; /* double links -- used only if free. */ struct malloc_chunk* bk; /* Only used for large blocks: pointer to next larger size. */ struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */ struct malloc_chunk* bk_nextsize; };
- top chunk
- 相当于分配区的顶部空闲内存(可能就是由brk调用控制的brk指针),当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
- 当top chunk大小比用户所请求大小还大的时候,top chunk会分为两个部分:User chunk(用户请求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成为新的top chunk。
- 当top chunk大小小于用户所请求的大小时,top chunk就通过sbrk(main arena)或 mmap(thread arena)系统调用来扩容。
- top chunk
- bins:意思是回收站,垃圾箱,这里指空闲空间,包括:
- Fast bin: 若干个定长空闲队列(不会立刻合并两个相邻的空闲空间)
- Unsorted bin:无尺寸限制
- 比 Fast bin 可容纳的最大 chunk 还要大的部分会放进这里
- Fast bin 进行合并后的 chunk 也会首先进入这里
- Small bin
- Large bin
- 主分配区 & 非主分配区(分配区管理着自己的一系列chunk)
- 每个分配区都能加锁,保证线程安全
- 多线程的时候,发起malloc的线程回去寻找没有加锁的分配区,若找不到则新开辟一个分配区(一旦新增分配区则不会减少)
- 非主分配区只能使用mmap来映射内存块
- 为避免竞争,可以使用thread cache,其改进如下:
- thread cache 即为每一个thread开辟一个独有的空间,从而避免竞争
- 每次malloc时,先去线程局部存储空间中找area,用thread cache中的area分配存在thread area中的chunk。当不够时才去找堆区的area
- C++11中提供了thread_local
- 优缺点:
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放
- 多线程锁开销大
- 内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。 比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用上
tcMalloc
- ThreadCache
- tcmalloc为每个线程分配了一个线程本地ThreadCache,小内存从ThreadCache分配(best fit),此外还有个CentralCache,ThreadCache不够用的时候,会从CentralCache中获取空间放到ThreadCache中。
- 小对象(<=32K)从ThreadCache分配,大对象从CentralCache分配。大对象分配的空间都是4k页面对齐的,多个pages也能切割成多个小对象划分到ThreadCache中。
- ThreadCache 维护着170多个不同大小的 FreeList;如果链表空了,则会从 CentralCache 中获取一些 page 并切割成相应大小放入链表中
- CentralCache
- 用 PageHeap 维护着一系列1-255page的链表,第256个链表用来存储大于255page的对象
- 优化点:
- ThreadCache会阶段性的回收内存到CentralCache里。 解决了ptmalloc2中arena之间不能迁移的问题。
- Tcmalloc占用更少的额外空间。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。Ptmalloc2使用最少8字节描述一个chunk。
- 更快。小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。 并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费。
jeMalloc
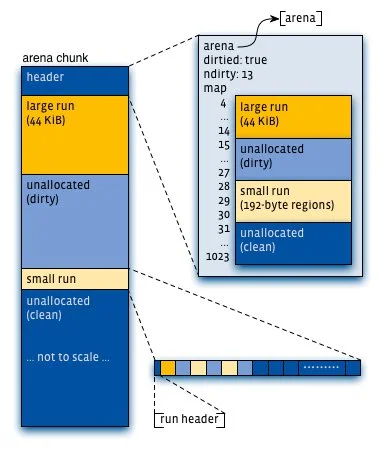
- 通过arena分配的时候需要对arena bin(每个small size-class一个,细粒度)加锁,或arena本身加锁。 并且线程cache对象也会通过垃圾回收指数退让算法返回到arena中。
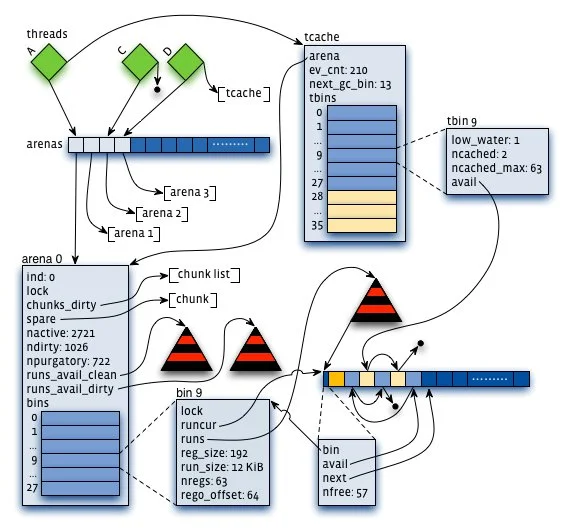
- 优化点
- Jmalloc小对象也根据size-class,但是它使用了低地址优先的策略,来降低内存碎片化。
- Jemalloc大概需要2%的额外开销。(tcmalloc 1%, ptmalloc最少8B)
- Jemalloc和tcmalloc类似的线程本地缓存,避免锁的竞争
- 相对未使用的页面,优先使用dirty page,提升缓存命中。
总结
在多线程环境使用tcmalloc和jemalloc效果非常明显。当线程数量固定,不会频繁创建退出的时候, 可以使用jemalloc;反之使用tcmalloc可能是更好的选择。
内存分配器(内存池)的场景要求每次分配必须是逻辑上连续的空间,并且任务退出后必然会释放内存,内存碎片的影响不会长期存在,而磁盘分配器的场景则会面临碎片长期存在,影响磁盘利用率的问题。
相关文章:
Design Purpose
为什么要 allocator
allocator 的作用就是提高写效率(写之前需要先分配空间),它又被称为空闲空间管理器,一般有下面几种基本的实现方案:
bitmap: 在linux中应用非常广泛,例如空闲空间管理,空闲inode管理,信号管理
- free list (Linked List of Free Blocks)
- 或许会和下面一条产生歧义,这里的free list指的是磁盘上每个空闲空间都会保存一些信息,比如下一个空闲空间的位置,这样就可以通过这个信息找到下一个空闲空间,从而实现分配。
- 实现简单,只需要在主存中保存一个指针
- 不支持随机访问,工作效率低,修改链表需要大量I/O 操作
- 空间越大性能越差,不适合大型文件系统
- free map/table
- 只能用于连续空间的分配,不支持离散空间的分配。
- 仅当有少量空闲区时才有好的效果,过多小的空闲空间会使得空闲表变得很大,占用太多内存资源
- 能够实现log(n)的分配时间,甚至常数时间的分配时间;但代价是free的时候需要合并相邻的空闲区,这个过程可能会很慢
设计目标及思路
这次希望做的是一个面向 LOSF 大量小文件(小于4MB)的高性能块设备分配器,同时可能会使用网络块设备(比如 ebs),因此单次io的延迟(约10ms)也可能远大于使用本地磁盘的延迟:
- 传统HDD 随机IO的延迟大约是8-12ms,IOPS 为 100-200
- 消费级SSD(NVME) 随机IO的延迟大约是20us,IOPS 为 400K
不同的设备特性千差万别,不同的负载场景也有巨大差异,因而分配器的设计在性能取舍上也会有所不同。
假如我们面对的是SSD这种块设备,并且需要支持较大的文件分配,那么我们可以放心大胆的使用bitmap来分block(4KB)管理磁盘空间,因为只要使用多个bitmap并且区分块组,那么就可以做到:
- 支持完全意义上的并行分配
- 将时间复杂度降到 $O(\sqrt{N})$,远小于 O(N)
- 内存消耗恒定,不会受到磁盘碎片分布的影响出现爆内存的情况
- 落盘方便,只需要将bitmap落盘即可
- 支持随机分配和连续分配,由于ssd擦除的特性,连续分配的性能会更好,因此可以尽量分配连续空间,但是如果连续空间不足,也可以分配离散空间。
- 可以加一层池化层将小空洞填上,这样可以牺牲一部分内存占用来提升分配性能
假如面对的是网络块设备,那么分块管理磁盘就一定会导致下游用户在读写块设备的时候需要进行多次的随机IO,虽然能够并发进行,但是总体的延迟还是会很高,因此我们需要尽可能进行顺序分配,这样(或许)可以将随机IO转化为顺序IO,从而提升性能。(待验证)
设计目标是面向小文件的高性能分配器:
- 还不错的磁盘空间利用率
- 可以接受的分配性能(越高越好,假如使用ebs,分配时间在1ms量级内都可以接受)
- 尽可能高的读写性能(连续分配优先)
- 内存占用要尽量优化
接口定义:
1
2
3
4
5
6
7
8
type BlockAllocator interface {
GetDisk() disk.Disk
AllocateContinuousBlocks(n uint64) (uint64, uint64, error)
TryAllocateBlocks(n uint64) (uint64, uint64, error)
FreeBlocks(start, end uint64) error
GetStatus() (uint64, uint64)
Shutdown() error
}
测试条件:
- 2TB 磁盘空间(如果分配器性能很好,则改成16TB测试)
- 负载为随机分配 0-4MB 大小范围内的分配请求,概率分布为平均分布,且不会随时间变化
- 每个分配好的块都有50%的概率在将来删除,使用一个map记录需要后续free的块,每跑一轮就批量free一次
代码指路:https://github.com/CodingPoeta/disk_alloc
Method 1 bitmap allocator
design 1
先完成一个bitmap的基础类,提供Set,Unset,Check接口,然后再在这个基础上实现一个bitmap分配器。
首先根据实际情况,可以确认现在大部分的SSD设备读写单元是4KB甚至更大,那么就使用 4KB 的大小来组织块设备空间,设备容量为2TB,那么总共有 2TB / 4KB = 512M 个块,因此需要 512M / 8 = 64MB 大小的bitmap来表示每个块的使用情况。
TryAllocateBlocks
这个接口用于尝试分配离散的块,采用的搜索策略是first fit,即从头开始搜索,找到第一个空闲块就返回。
AllocateContinuousBlocks
这个接口用于尝试分配连续的块,采用的搜索策略也是first fit,找到第一个满足大小的连续空闲块就返回。
Test result 1
测试负载类型:0-4MB大小范围内,平均分布的随机 allocate 请求,已经分配的空间有一定50%概率会在随机一段时间后删除。
离散分配测试结果:
2023/04/29 09:31:01 RandomTest 0.5 done, 10000 rounds in 0.15 seconds, disk space: 0.990
2023/04/29 09:31:01 RandomTest 0.5 done, 10000 rounds in 0.03 seconds, disk space: 0.986
...
2023/04/29 09:31:04 RandomTest 0.5 done, 10000 rounds in 0.17 seconds, disk space: 0.347
2023/04/29 09:31:05 RandomTest 0.5 done, 10000 rounds in 0.25 seconds, disk space: 0.342
2023/04/29 09:31:05 RandomTest 0.5 done, 10000 rounds in 0.66 seconds, disk space: 0.337
2023/04/29 09:31:21 RandomTest 0.5 done, 10000 rounds in 15.29 seconds, disk space: 0.332
2023/04/29 09:32:14 RandomTest 0.5 done, 10000 rounds in 53.31 seconds, disk space: 0.328
2023/04/29 09:33:28 RandomTest 0.5 done, 10000 rounds in 74.22 seconds, disk space: 0.323
...
- 当空间利用率在65%以内时,分配性能都能在100000次/s左右,平均分配时间在10us以内。
- 当空间利用率达到70%时, 由于golang测试程序需要记录未来需要free的磁盘空间,free掉之后需要GC;此时分配出来的空间越来越不连续,一个较大分配请求很可能分配到的是成百上千的小碎片,从而free后产生的内存垃圾也急剧增加,GC的频率时长急剧增加,后续测试难以为继,此时算上测试程序GC的时间,分配性能是<500次/s
- 其原因主要是first fit的分配策略会源源不断产生越来越小的空洞,这些空洞导致离散分配的空间随着时间的推移越来越支离破碎,即使分配出来了许多离散的空间,但其读写性能会极其低下,此时分配器已经完全不可用了。
连续分配测试结果:
2023/04/29 09:27:19 RandomTest 0.5 done, 10000 rounds in 0.59 seconds, disk space: 0.990
2023/04/29 09:27:23 RandomTest 0.5 done, 10000 rounds in 3.43 seconds, disk space: 0.986
2023/04/29 09:27:29 RandomTest 0.5 done, 10000 rounds in 6.02 seconds, disk space: 0.981
2023/04/29 09:27:37 RandomTest 0.5 done, 10000 rounds in 8.25 seconds, disk space: 0.976
2023/04/29 09:27:48 RandomTest 0.5 done, 10000 rounds in 10.77 seconds, disk space: 0.971
2023/04/29 09:28:03 RandomTest 0.5 done, 10000 rounds in 15.25 seconds, disk space: 0.966
2023/04/29 09:28:20 RandomTest 0.5 done, 10000 rounds in 16.79 seconds, disk space: 0.962
...
- 这里连续分配采用的策略也是first fit,因此随时间推移,块设备前部区域有越来越多已经被分配的空间或free产生的空洞,一次分配中所需要搜索的区间也越来越大,分配性能也就会线性下降
- 由于大量碎片的存在,bitmap 查找连续空间的性能也会导致程序局部性很差
并发性能: 由于bitmap分配器全局共享一个bitmap,因此并不具备并行能力,并发性能很差,这里不做测试。
optimize
bitmap分配器的性能瓶颈在于first fit的分配策略会源源不断产生越来越小的空洞,假如使用best-fit分配策略则每次分配都会扫描全部地址空间,显得更加得不偿失,实际上对于需要频繁分配回收产生空洞的场景,仅仅依赖bitmap还不够。
优化方案:
使用multi bitmap来管理,原先使用一整个bitmap的时间复杂度是O(N),现在使用L个bitmap,每个bitmap管理M个块,即 N = L * M,那么我们可以将时间复杂度降到O(N^0.5)
新增一层池化层,将free产生的碎片用链表管理起来,下次需要的时候直接从链表中取出,这样可以将分配性能提升到O(1),但是会牺牲一部分内存占用;更关键的是很可能能避免产生越来越多的碎片,从而保证稳定的分配性能。
Method 2 multi-bitmap allocator
design 2
按照 4KB 的大小组织块设备空间,设备容量增加为16TB,那么总共有 16TB / 4KB = 4G 个块,将这些块按照每 64K 个块为一组,可以分为 64K 组。
每组除了使用bitmap管理块的使用情况外,还可以新增块组内使用率的信息,这样就可以在分配的时候优先分配使用率低的块组,从而能够尽可能均衡地利用整个块设备。
如果有需要提高性能,还可以设计一个空闲链表来管理free产生的空洞,由于我后续还要设计一个原理相同的池化层,所以就不需要了。
TryAllocateBlocks / AllocateContinuousBlocks
随机选取一个空闲空间合适的块组,然后使用于bitmap allocator一样的思路进行分配。
Test result 2
由于性能相较于bitmap allocator有了很大的提升,所以我将测试的块设备大小改为了16TB,轮数增加到了100000,测试结果如下:
离散分配测试结果:
2023/04/29 09:43:56 RandomTest 0.5 done, 100000 rounds in 0.66 seconds, disk space: 0.988
2023/04/29 09:43:56 RandomTest 0.5 done, 100000 rounds in 0.41 seconds, disk space: 0.982
...
2023/04/29 09:45:05 RandomTest 0.5 done, 100000 rounds in 0.52 seconds, disk space: 0.010
2023/04/29 09:45:06 RandomTest 0.5 done, 100000 rounds in 0.58 seconds, disk space: 0.004
2023/04/29 09:45:07 RandomTest 0.5 done, 100000 rounds in 0.56 seconds, disk space: 0.003
2023/04/29 09:45:07 RunTest error: no free blocks
- 离散分配的性能极好,写满时磁盘利用率为99.7%,分配性能为200000次/s,平均每次分配时间为5us
- 管理16TB磁盘时,内存占用为 16TB / 4KB /8 = 512MB,并且稳定不变
连续分配测试结果:
2023/04/29 09:47:15 RandomTest 0.5 done, 100000 rounds in 0.17 seconds, disk space: 0.988
2023/04/29 09:47:16 RandomTest 0.5 done, 100000 rounds in 0.15 seconds, disk space: 0.982
...
2023/04/29 09:47:57 RandomTest 0.5 done, 100000 rounds in 0.44 seconds, disk space: 0.308
2023/04/29 09:47:57 RandomTest 0.5 done, 100000 rounds in 0.44 seconds, disk space: 0.302
...
2023/04/29 09:48:29 RandomTest 0.5 done, 100000 rounds in 2.64 seconds, disk space: 0.033
2023/04/29 09:48:34 RandomTest 0.5 done, 100000 rounds in 4.07 seconds, disk space: 0.027
2023/04/29 09:48:42 RandomTest 0.5 done, 100000 rounds in 8.05 seconds, disk space: 0.021
2023/04/29 09:49:18 RandomTest 0.5 done, 100000 rounds in 35.98 seconds, disk space: 0.016
2023/04/29 09:52:20 RandomTest 0.5 done, 100000 rounds in 182.41 seconds, disk space: 0.014
2023/04/29 09:52:20 RunTest error: no free blocks
- 连续分配的性能也非常好,写满时空间利用率为98.6%,
- 空间利用率低于95%时,分配性能为至少100000次/s,平均每次分配时间为10us
- 磁盘几乎写满时,分配性能大大降低,大约为500次/s,平均每次分配时间为2ms,但是对下游客户来说依然可用
注:即使将free的概率提高到80%(会形成更多空洞),分配性能依然很高,即空间利用率低于95%时,分配性能为至少100000次/s,平均每次分配时间为10us;唯一不同的是写满时空间利用率下降到97.5%。
连续分配并发性能: 由于划分了多个块组,每个块组都可以独自管理自己的空间,因此并发性能很高。 在4核8线程的i5mac上进行并发度为8的测试结果为:
- 与单线程测试相比,性能下降可以忽略不计
- 空间利用率低于95%时,每个线程分配性能都有至少100000次/1.3s,平均每次分配时间为13us (相比单线程性能略有下降,主要是电脑性能问题所致)
- 磁盘几乎写满时,分配性能大大降低,其性能下降程度与单线程相比相差无几,大约每个线程为400次/s,平均每次分配时间为2.5ms,但是对下游客户来说也依然可用
Method 3 linked list pooling allocator
design 3
// TODO
Test result 3
这个linked list pooling层的设计原理就决定了它的连续分配性能是最优秀的,时间复杂度为O(1),对非连续分配不做测试
测试条件为池化层占据100%的磁盘空间,即完全使用池化层的链表管理机制来管理磁盘空间,其本质已经不再是池化,而是基于链表的空闲空间分配器。
由于性能极好,磁盘空间设定为16TB
单线程连续分配测试:
2023/04/29 10:41:54 PreAllocate done
2023/04/29 10:41:54 RandomTest 0.5 done, 100000 rounds in 0.07 seconds, disk space: 0.988
2023/04/29 10:41:55 RandomTest 0.5 done, 100000 rounds in 0.06 seconds, disk space: 0.982
...
2023/04/29 10:42:00 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.487
...
2023/04/29 10:42:05 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.003
2023/04/29 10:42:05 RandomTest 0.5 done, 100000 rounds in 0.03 seconds, disk space: 0.000
2023/04/29 10:42:05 RunTest error: context canceled
2023/04/29 10:42:05 RunTest done, 0.0000
- 性能远超前面的 multi bitmap 分配器
- 写满时空间利用率 >99.9%,分配性能自始至终为都大于100000次/0.05s,平均每次分配时间为0.5us,时间复杂度是O(1)
- 内存占用为变化值,测试过程中allocator最大内存占用大约为 512MB
并发连续分配测试:
2023/04/29 10:48:04 RandomTest 0.5 done, 100000 rounds in 0.51 seconds, disk space: 0.910
2023/04/29 10:48:04 RandomTest 0.5 done, 100000 rounds in 0.52 seconds, disk space: 0.908
2023/04/29 10:48:04 RandomTest 0.5 done, 100000 rounds in 0.53 seconds, disk space: 0.907
...
2023/04/29 10:48:19 RandomTest 0.5 done, 100000 rounds in 0.71 seconds, disk space: 0.000
2023/04/29 10:48:19 RandomTest 0.5 done, 100000 rounds in 0.71 seconds, disk space: 0.000
2023/04/29 10:48:19 RandomTest 0.5 done, 100000 rounds in 0.71 seconds, disk space: 0.000
2023/04/29 10:48:19 RunTest error: context canceled
2023/04/29 10:48:19 RunTest done, 0.0239
- 由于内部具有分桶的路由设计,因此实际上具有一定的并行能力。但部分情况下会出现largbin的争用,从而导致线程频繁阻塞,并发性能低于单线程性能,但是依然非常优秀,暂时不进行优化。
C/S architecture
design 4
// TODO
Optimize: client side caching
用前面写的linked list pooling allocator把客户端包一层即可,这样就能够做到每次预分配一块大空间,然后在客户端进行分配,这样就能够大大提高分配性能。
Test result 4
不带池化缓存的CS架构性能测试:
2023/04/29 13:08:48 RandomTest 0.5 done, 100000 rounds in 11.40 seconds, disk space: 0.904
2023/04/29 13:09:05 RandomTest 0.5 done, 100000 rounds in 11.60 seconds, disk space: 0.857
2023/04/29 13:09:22 RandomTest 0.5 done, 100000 rounds in 10.94 seconds, disk space: 0.809
...
2023/04/29 13:11:45 RandomTest 0.5 done, 100000 rounds in 10.95 seconds, disk space: 0.428
...
2023/04/29 13:14:18 RandomTest 0.5 done, 100000 rounds in 13.12 seconds, disk space: 0.046
2023/04/29 13:14:40 RandomTest 0.5 done, 100000 rounds in 15.63 seconds, disk space: 0.000
2023/04/29 13:14:40 RunTest error: context canceled
2023/04/29 13:14:40 RunTest done, 0.0000
- 平均分配性能平均约为100us,主要受到跨进程通信的延迟影响
带池化缓存和预分配的CS架构性能测试:
2023/04/29 13:48:17 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.904
2023/04/29 13:48:17 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.857
...
2023/04/29 13:48:18 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.427
...
2023/04/29 13:48:18 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.094
2023/04/29 13:48:18 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.046
2023/04/29 13:48:18 RandomTest 0.5 done, 100000 rounds in 0.05 seconds, disk space: 0.000
2023/04/29 13:48:18 RandomTest error: rpc error: code = Unknown desc = not enough space
- 平均分配性能回到了0.5us,性能提升了200倍
- 2TB磁盘空间的情况下,每次预分配设定为16GB
Thinking
从前面的对比实验中可以看到,不论是基于空闲链表还是基于multi-bitmap的思路,在这里都是可行的。
而空闲链表分配器面向这个测试场景其性能优势尤为明显,而且写满时磁盘空间利用率也非常高,这一点或许比较反直觉,但是一旦我们考虑到尺度的问题就能够明白了。
- 首先,在2020年代,块设备大小一般能够达到1-16TB,最小读写单元一般为4KB
- 在前面提到过,这个分配器设计目标是为了支持大量小文件的分配,因此我们假设每个文件大小为0-4MB,那么每个文件占用的最小读写单元范围为0-1024个块
- 池化方案中设计了 fastbin 和 largebin 两种桶,其中 fastbin 用来管理所有已经被切分成小块的0-4MB的空闲空间,而 largebin 用来管理所有还未被分配的空间
- 当fastbin中对应的桶为空时,分配器会从largebin中切下一块空间,分配给用户
这里的关键就是,我们需要支持的分配大小相对于4KB这个尺度而言足够小,这也决定了fastbin的桶非常非常深,因此在大多数情况下,我们都能够从fastbin中分配到空间,而不需要从largebin中分配,并且free产生的碎片也都能顺利进入fastbin回收再利用。
当某一次分配失败时,此时剩余未分配空间占总空间比值的期望其实极低,在前面这种场景下,其期望值甚至低于0.1%。
不妨思考一个问题:
假设有N个桶,从1-N编号,记它们的编号为n;每个桶中都有M个苹果,有一只猴子每天都会随机找其中一个桶,从中偷走一个苹果,请问当猴子发现自己选中的桶空了的那天:
- 假设这一天是第D天,请问D的期望和分布?
- 请问还剩多少个苹果?求出期望和分布。
- 假定每个桶的编号n就是苹果的价格,请问剩下的苹果值多少钱?求出期望和分布。
- 假定猴子每天随机选桶的时候,并不是均匀分布的随机,而是正态分布,或者其他某种概率分布,重新解一下上面的问题。
有兴趣的朋友可以挑战一下这道题,为了避免浪费时间,可以先看看这里。
这几个问题的解析解非常难求,我的选择是用python做一下蒙特卡洛抽样,然后由于遍历空间太大而失败了…
经过正确分析之后能够得到一个结论:当M远大于N的时候,剩下的苹果占比极低,这恰好跟我们前面的实验结果一致。
如果你对这个分析过程感兴趣的话,请看附录。
其实,这个问题就是分配器工作场景的一个同构模型,fastbin 正好充当了一个采样器的角色,fastbin中各个桶的深度分布就是过去用户负载free的概率分布。如果用户负载allocate和free的概率分布是相同的并且在一个较长的周期内是稳定的(用随机过程的术语的话,称为平稳过程),那么fastbin中保存的“碎片”跟后续新增的负载能够恰好匹配,这样就能够保证fastbin中的碎片能够被充分利用,磁盘利用率会非常高。并且只要这个概率分布的期望不是极端的小,那么整体的内存占用也不会比bitmap分配器多。
现实中,用户负载的概率分布并不是稳定的,比如有一个权重很大的0-1MB文件相关的服务,它上线和下线都会对这里的分配器产生冲击。
有没有办法解决这个问题?答案依然是根据尺度来处理,如果这个负载很重并会长时间存在,且自身是稳定的,但跟其它负载不能兼容,那就给他单独的块设备和分配器。如果是个短期的负载或者小负载,那么它对整体的影响也不会太大。
所以根据上述分析就能得知,这个linked list pooling分配器已经足够完美的适配大部分LOSF的场景了。
如果一定要钻牛角尖,在什么情况下linked list pooling分配器会出现性能问题或可用性问题呢?
当分配器工作前期很长时间内(长到足以将largebin中的缓冲消耗完)负载范围是0-1MB,并且有80%概率free掉;后续负载立刻变为3-4MB,那么fastbin中的碎片就会被浪费掉,磁盘利用率会低至20%。
让我们归纳一下,会使 linked list pooling 分配器失效的极端负载需要有如下特征:
- 负载的概率分布会出现突变,且差异需要比较明显,例如前期是正态分布,后期是两端分布
- 突变前后,负载都需要能够稳定工作较长时间,在磁盘空间尺度上,大致需要在磁盘空间的这个量级,比如突变前负载最大占用了70%甚至占满磁盘空间,然后释放掉了其中的80%后下线;新的突变后的负载上线后不久就会发现分配器失效了,而此时磁盘利用率还未过半。
- 假如负载并不是局限在0-4MB,而是远大于此,例如0-1GB,那么fastbin的桶就会非常浅,也就是完全失效。
倘若想要解决上述问题,工程上可以给这种特殊的重负载打上标签,然后:
- 让他们使用独享的分配器和块设备(类似属性的负载可以放一起)
- 或者负载下线前进行一次统一的compaction操作,将碎片重新整理到一起,而这个操作的时间复杂度时O(nlogn)
- 离线操作,不影响在线服务,因此耗时完全能够接受
- bitmap 的优势之一也正在此:即free操作的时间复杂度是O(1),并且不需要额外的compaction操作来合并碎片
如何 compaction
我们先衡量一下compaction的代价:
- bitmap allocator:
- 分配的时间复杂度是O(n),free的时间复杂度是O(1),无需额外compaction
- linked list pooling allocator:
- 分配的时间复杂度是O(1),free的时间复杂度是O(1),compaction的时间复杂度是O(nlogn)
- search tree allocator:
- 分配的时间复杂度是O(logn),free的时间复杂度是O(logn),无需额外compaction
最简单的思路当然是把linked list pooling与其他的分配器组合一下咯,比如:
- 同时使用bitmap 和 linked list,这样可以做到分配性能为O(1),free性能为O(1),compaction性能为O(n),但是这样的话,内存占用就会变大,而且compaction操作可以离线进行,从O(nlogn)优化到O(n)的收益并不大
- 用一颗查找树来维护有序性也能降低compaction的时间复杂度,但是由于每次free都需要维护树的有序性,因此free的性能会变差,而且内存占用也会变大,可见收益并不明显
关于尺度
前面一直在说尺度很重要,更重要的考虑的是空间尺度,其实时间尺度也非常重要,比如
- 当一个链路中某一个环节耗时占比本来就很低,那么即使优化了也不会有太大的收益,反而会增加复杂度。
- 与人交互的应用,如果响应时间超过了人的感知,那么优化的收益也不会太大。
在这里就顺便记录一下当今计算机世界中常见的时间尺度。
- cpu 周期
- 时钟周期:主频的倒数,常见的是 0.2-0.4ns
- 指令周期:从取指到指令执行结束的时间,因为流水线的存在,指令周期会比时钟周期长
- RISC 架构:以ARM7为例,简单的算术和逻辑运算是单周期的,复杂的(乘除法)可能有2-5个周期
- CISC 架构中简单的指令执行快,复杂的指令执行慢
- Branch mispredict: 3ns
- mutex lock/unlock: 20ns
- L1 cache: 1.1ns
- L2 cache: 3.3ns
- L3 cache: 12.8ns
- L4 cache: 42.4ns
- Main memory: 60-120ns – 5-10$/GB
- 从内存顺序读取 1 MB: 3,000 ns
- SSD随机读: 16,000ns with PCIE4.0 – 0.1-0.2$/GB
- SSD顺序读取 1 MB: 49,000 ns
- 同一个数据中心往返: 500,000 ns
- 磁盘顺序读取 1 MB: 825,000 ns
- 磁盘寻址: 2,000,000 ns (2 ms)
- 美国发送到欧洲的数据包: 150,000,000 ns(150 ms)
UCB 为记录不同年代的计算机操作耗时做了一个动态网页,今后有需要了都可以去逛逛,记住了就能作为心中的一杆尺子。
比如,从服务器的内存中请求数据会比直接从磁盘上读取要快。